Prompt Caching in Production: What the Numbers Actually Look Like
We added Anthropic prompt caching to a document analysis tool. Here’s the real cost and latency data after 30 days.

Prompt caching sounds like an obvious win on paper — pay less, wait less. The reality is more nuanced. After running it in production for 30 days across a document analysis tool processing roughly 4,000 requests per day, here’s what we actually measured.
What We Were Building
The tool takes uploaded documents (contracts, reports, specs) and answers structured questions about them. The system prompt includes task instructions and a detailed output schema — about 2,800 tokens that stays identical across every request. The variable part is the document content and the user’s question.
Why Caching Seemed Like a Good Fit
The classic use case for prompt caching is exactly this: a large static prefix followed by a small dynamic suffix. Our system prompt was large, static, and hit on every request. The only reason we hadn’t enabled caching earlier was uncertainty about how much of the cost was actually in that prefix versus the document tokens.
Setting It Up
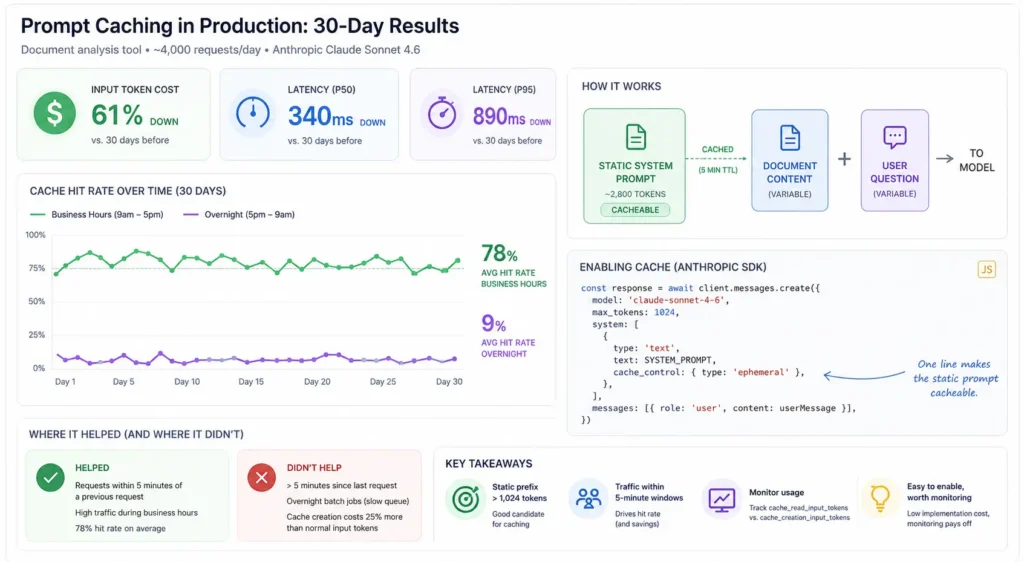
Enabling caching with the Anthropic SDK is a one-line change per cacheable block:
const response = await client.messages.create({
model: 'claude-sonnet-4-6',
max_tokens: 1024,
system: [
{
type: 'text',
text: SYSTEM_PROMPT,
cache_control: { type: 'ephemeral' },
},
],
messages: [{ role: 'user', content: userMessage }],
})
The cache has a 5-minute TTL by default. For our workload — bursty during business hours, quiet overnight — this meant high hit rates during the day and cold caches every morning.
Measuring Cache Hit Rate
The API response includes usage.cache_read_input_tokens and usage.cache_creation_input_tokens. We logged both to a simple time-series table for the first week before drawing any conclusions.
The Numbers
Over 30 days with caching enabled versus the 30 days before:
- Input token cost: down 61%
- Average latency (p50): down 340ms
- Average latency (p95): down 890ms
- Cache hit rate during business hours: 78%
- Cache hit rate overnight: 9%
Where It Didn’t Help
Requests that arrive more than 5 minutes after the previous one get no benefit — they pay the cache creation cost, which is 25% more than a normal input token. For our overnight batch jobs that process documents on a slow queue, caching was a net negative. We disabled it for that queue specifically.
Practical Recommendations
Prompt caching is worth enabling if your static prefix is over 1,024 tokens and you have at least moderate request volume within any 5-minute window. The implementation cost is minimal. The monitoring cost — making sure you’re not accidentally paying cache creation premiums on infrequent paths — is where you should spend your time.
The 5-minute TTL is the number to build your intuition around. If your traffic pattern is spiky or async, profile your inter-request gaps before assuming caching will save money.